توسعه آنتیبادیهای درمانی با شتاب هوش مصنوعی: بینشهای عملی - داروخانه آنلاین مدیسینا
روشهای پیشرفته برای تجزیه و تحلیل آنتیبادی
آنتیبادیها به دلیل ویژگیهای خاص خود مانند هدفگیری دقیق، میل ترکیبی بالا و تطبیقپذیری، بزرگترین دسته از داروهای بیولوژیک محسوب میشوند. پیشرفتهای اخیر در هوش مصنوعی، امکان ایجاد بازنماییهای غنی از اطلاعات در محیطهای محاسباتی (in silico) از آنتیبادیها، پیشبینی دقیق ساختار آنتیبادی از توالی و تولید آنتیبادیهای جدید با ویژگیهای خاص برای بهینهسازی خواص توسعهپذیری را فراهم کرده است. در اینجا، روشهای پیشرفته برای تجزیه و تحلیل آنتیبادی را خلاصه میکنیم. این منبع ارزشمند به عنوان مرجعی برای کاربرد روشهای هوش مصنوعی در تجزیه و تحلیل مجموعه دادههای توالییابی آنتیبادی خواهد بود.
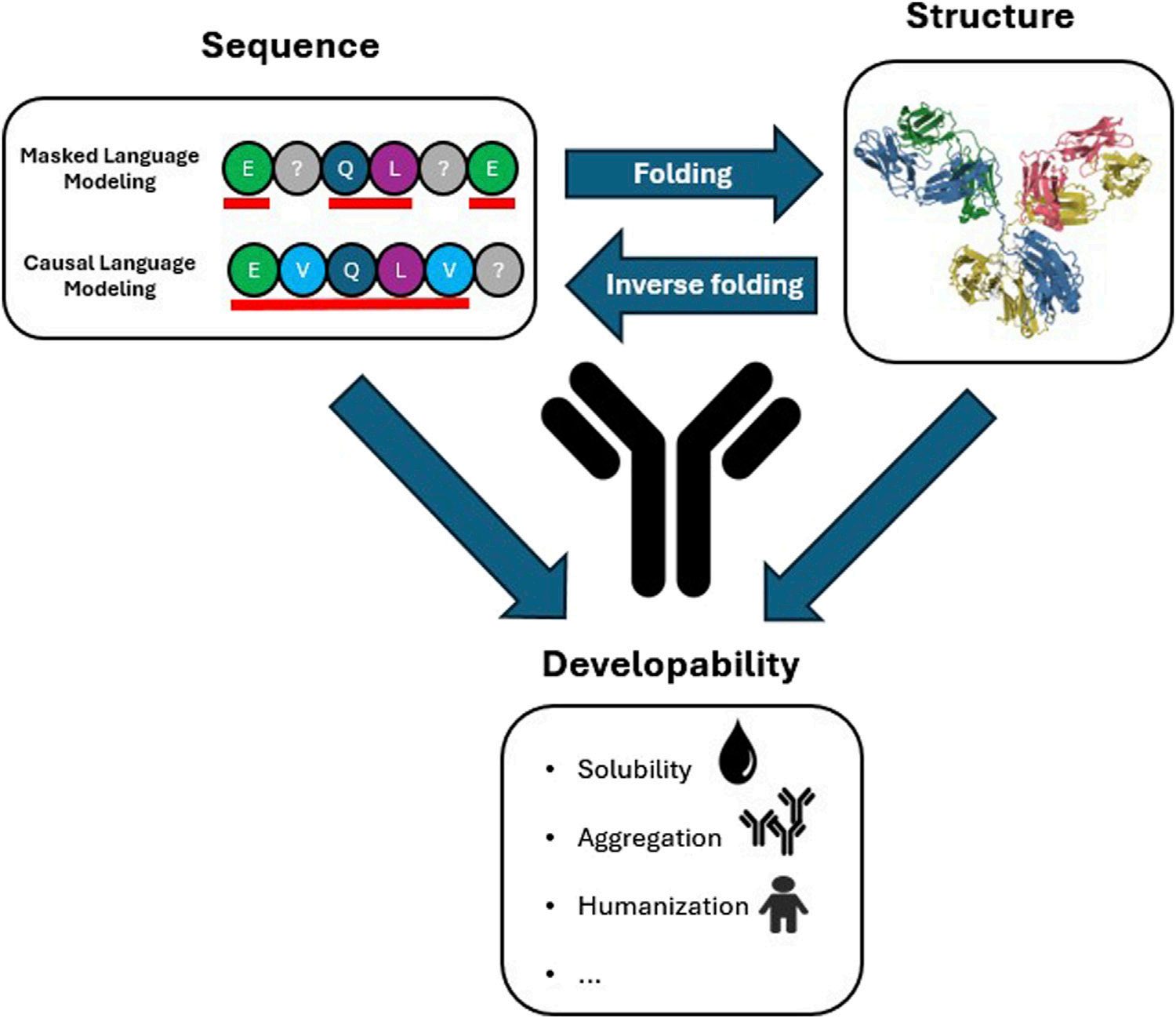
شکل ۱:
این شکل، اطلاعات توالی و ساختار آنتیبادی را در رابطه با ویژگیهای توسعهپذیری نشان میدهد. استراتژیهای پیشبینی مدلسازی زبان پوشاندهشده (مانند BERT) و مدلسازی زبان خودبازگشتی علّی (مانند GPT) برجسته شدهاند. باقیماندههای زیرخطدار قرمز، باقیماندههایی هستند که برای آموزش مدل برای پیشبینی باقیماندههای پوشاندهشده استفاده میشوند (پوشاندهشده و باقیمانده بعدی علّی با علامت سوال خاکستری نشان داده شده است). ساختار آنتیبادی نماینده، ساختار ایمونوگلوبولین (PDB: 1IGY) است. فلشها جریان اطلاعات از توالی به ساختار (مدلهای تاخوردگی)، از ساختار به توالی (مدلهای تاخوردگی معکوس) و اینکه ویژگیهای توسعهپذیری توسط هر دو توالی و ساختار آنتیبادی تعیین میشوند را نشان میدهند.
آنتیبادیها بزرگترین دسته از داروهای بیولوژیک هستند و پیشبینی میشود تا سال ۲۰۲۵، بازار آنها به ۳۰۰ میلیارد دلار برسد. آنها برای درمان سرطان، بیماریهای خودایمنی و عفونی استفاده میشوند، زیرا میتوانند به گونهای طراحی شوند که هر آنتیژنی را با ویژگی و میل ترکیبی بالا شناسایی کنند. کشف آنتیبادی به طور سنتی با تکامل هدایتشده با استفاده از روشهای آزمایشگاهی مانند هیبریدوما یا نمایش فاژ انجام میشود. اگرچه این روشها به خوبی تثبیت شدهاند، اما همچنان پرهزینه، زمانبر و به دلیل چالشهای آزمایشگاهی مستعد شکست هستند.
معرفی توالییابی نسل جدید (NGS) برای غربالگری آنتیبادی به جای برداشت تصادفی کلنی، امکان پوشش تنوع توالی بسیار بیشتر، دامنه میل ترکیبی گستردهتر و جداسازی توالیهایی که اپیتوپهای متمایز را هدف قرار میدهند، فراهم کرده است. توالییابی با خوانش کوتاه به یک زنجیره واحد، یا زنجیره سنگین (VH) و زنجیره سبک (VL) محدود میشود، در حالی که خوانشهای طولانی میتوانند اطلاعات جفتی هر دو زنجیره را به دست آورند و درک ما از وابستگیهای باقیمانده بین زنجیرهها را افزایش دهند.
به تازگی، هوش مصنوعی، به ویژه در زمینههای یادگیری عمیق و پردازش زبان طبیعی، پیشرفت سریعی را تجربه کرده است و زیستشناسی از آن بهره زیادی برده است. یک مثال قابل توجه، مدل AlphaFold2 برای زیستشناسی ساختاری است که پیشبینی ساختار پروتئین مبتنی بر توالی را به دقت آزمایشگاهی نزدیک کرده است.
موفقیت معماری ترانسفورمر در پردازش زبان طبیعی منجر به ایجاد مدلهای زبان بزرگ شده است، مدلهای آماری که روی مجموعههای بزرگی از متون آموزش داده شدهاند تا شباهت معنایی بین کلمات را در قالب بازنماییهای برداری، به نام embedding، بدون تکیه بر برچسبهای پرهزینه و دشوار به دست آمده، ثبت کنند.